
2024년 막바지를 향해 달리는 중,
짧고 굵게 후다다닥 지나갔지만 동시에 배운 것도 정말 많은 IR 경진대회에 대해 리뷰한다.
기간은 단 4일! 월요일에 서버 만들고 데이터 다운로드해서 베이스라인 땅! 시작하고,
수요일에 멘토링을 한 번 받은 뒤에, 목요일까지 결과를 제출하고, 금요일에 발표 및 랩업 세미나로 정리하는 타이트하고 빡센 일정이였다.

<대회 소개>
- "질문"이 들어오면, 질문과 연관된 "적절한 문서"를 찾고, 그 문서를 참조해서 적절한 답변을 생성한다.
- 대회에서는 답변을 확인하지 않고, 답변을 위해 참조한 문서 3개(top k)를 뽑아서, 이 3개 문서가 잘 추출됐는지로 평가한다.
- 임베딩 생성 모델, 검색 엔진, LLM을 활용할 수 있다.
- 학습 데이터로 주어지는 문서와 쿼리 모두 jsonl 형태.
이번에 우리 조에는 4명의 팀원이 있었지만, 2명이 개인적인 사정으로 대회에 불참하게 되어 나와 다른 분 1명. 이렇게 둘이서 대회 팀플을 꾸려가게 됐다. 다행(?)히도 바로 이전 NLP 경진대회에서도 같은 조를 하면서 합을 맞춰봤던 경험이 있어 이번에도 함께 하는데 수월했다. 그리고 갠적으로 2명이서 하니까 리더보드에 제출횟수도 하루에 15개씩 있었는데 눈치보지 않고 마구 제출해볼 수 있어서 솔직히 좋았다. 또 각자 스타일이 달라서 원하는 방향으로 시도해보고 의견도 좀 더 딥하게 공유할 수 있었던 것 같다.
<대회 과정>

일단 우리 팀은 두 명이였기 때문에 각자 원하는 스타일을 시도해보기로 했다. S님은 지난 번에도 LLM의 성능을 최고로 끌어내어 높은 점수를 만들었던 경험이 있으셔서 그런지, 이번에도 일단 베이스라인 코드 안따라가고 LLM에 처음부터 끝까지 다 넣어보는 방법을 먼저 시도했다. 그러니까 문서 json파일을 주고, 쿼리 json파일을 보고 가장 연관된 문서 3개를 뽑게 하는 방식인 셈. 그런데 예상 외로 퍼블릭에서 점수가 높지 않았다. 0.7 정도!
반면 나는 베이스라인을 먼저 익히고 엘라스틱서치를 사용해서 검색 방식을 변화해보거나 프롬프트를 바꿔보는 것으로 처음에 시작했다. 엘라스틱서치를 까는 것부터가 난관이였는데(심지어 맥북에는 또 안깔려서 걍 서버에서 실행), 베이스라인 코드를 하나하나 이해하는 것에 시간이 꽤 많이 들었다. 요약해서 말하자면, 쿼리를 보고 LLM에게 보낸 뒤에 과학 관련 질문인지 아닌지 판별하게 해서, 과학 질문이면 키워드를 뽑고(standalone_query), 이 키워드를 바탕으로 sparse / dense 검색 방식을 사용해 엘라스틱서치로 문서를 검색하는 방법이다.

엘라스틱서치에는 임베딩된 문서가 들어가 있다. 검색 방식을 조합해가면서 실험을 하다가 멘토링을 받게 됐고, 멘토링에서 임베딩 모델을 더 다양하게 사용해볼 것을 추천해주셔서 그때부터 임베딩을 바꿔봤다. 오픈ai 임베딩이 가장 점수가 잘 나오고 있었고, 솔라 임베딩을 사용하려고 했는데 엘라스틱 서치에 안들어가서 포기해야하나 하고 있었다.

snunlp/KR-SBERT-V40K-klueNLI-augSTS
BM-K/KoSimCSE-bert
OpenAI text-embedding-3-small
Solar embedding
klue/bert-base
BAAI/bge-large-en-v1.5 -> 이거 m3로 썼어야 하는데 내가 잘못 사용함;
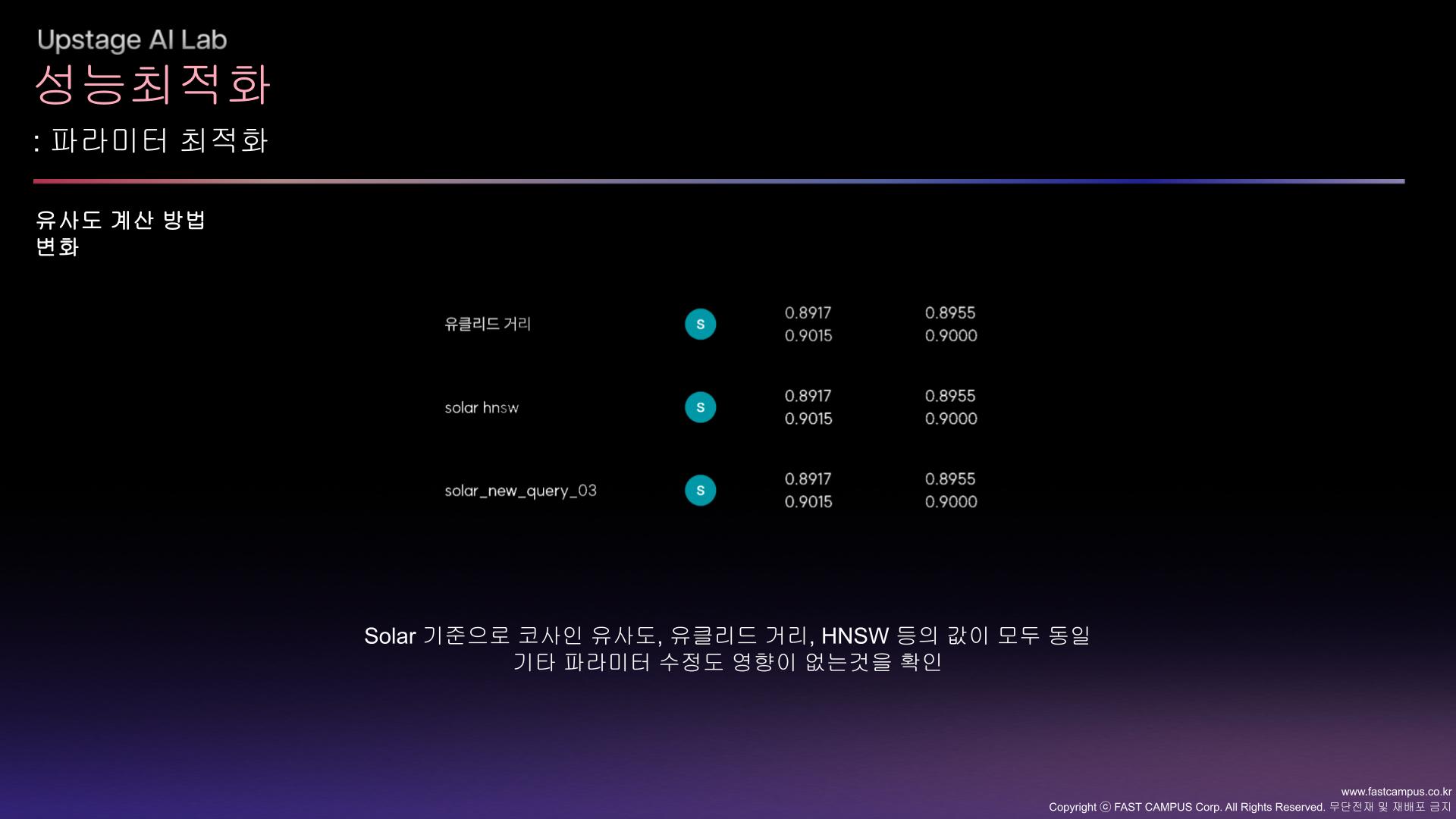
그런데 이때 S님이 solar 임베딩 사용해서 코사인 유사도로만 쿼리와 문서의 유사도를 계산했는데 그게 점수가 대박 높게 나왔다. 일단 솔라 임베딩이 성능이 가장 좋게 나오는 걸 확인한 이상, 나도 어떻게든 엘라스틱서치 안에 솔라 임베딩한 문서를 집어넣어볼라고 애를 썼다. PCA도 해봤는데 계속 차원이 다르다고 나와서 안됐고, 앞부분 2048만 잘라서 사용하니까 들어는 갔는데, 결과가 이상하게 뽑혀서 사용할 수가 없었다. 그래서 S님이 솔라 임베딩으로 벡터화시킨 쿼리랑 문서 파일을 pkl 파일로 주셨고, 그걸 사용하는 방식으로 해보려고 했다.
임베딩을 고정한 뒤로는 좀 더 다양한 방식을 시도해보려고 했다.
유사도 계산 방식을 바꾸는 방법
질문을 재작성해보는 방식


LLM에게 리랭킹시키는 방법

슬라이드에는 안적었지만 오픈ai와 솔라로 임베딩한 각각 문서 중에서 쿼리와 유사하게 계산된 문서들 후보를 10개씩 모으고, 겹치는 애들을 모아보는 방법도 생각했는데 구현은 못했다.
여기까지 달린 최종 결과는!
2등!
사실 여기서 점수나 등수가 그렇게 중요하다고 생각하지 않지만 어쨌든 지표 삼아서 보일 수 있는 게 이것 뿐.. 두명이서 한거 치고 뿌듯한(?) 결과물이 나와 다행이였고, 점수를 이렇게 높게 올려주신 S님께 넘 감사했다.

<프로젝트 이후, 앞으로 집중할 것>
RAG
요즘 굉장히 핫하다는 RAG. 갠적으로 AI를 공부해야겠다고 생각하게 된 직접적인 계기가 됐던 기술도 RAG였으니, 이번 프로젝트는 지금까지 공부한 것들의 최종 목적같은 느낌이였다. 부트캠프 처음 시작하면서 했던 랭체인과 그때 했던 라그는 뭔가 간보기 같은 느낌이였다면 지금은 훨씬 원론적인 느낌.
RAG의 기본 개념은 참조할 수 있는 데이터베이스를 주고, 그 안에서 정확한 답을 찾아서 답변할 수 있게 만드는 것이기 때문에 기본적으로 "데이터베이스"를 저장할 곳이 필요하다. 랭체인때는 벡터DB라고 종류 2가지밖에 몰랐고 그마저도 배경에 대해 아무것도 몰랐는데, 이번 플젝을 통해 엘라스틱서치라는 상용화된 툴이 있다는 것도 알게 됐다.
-> 엘라스틱서치에 문서를 저장해두고(벡터화하거나 뭐 다른 방식으로도) 그걸 활용하게 하는 것! 이걸 잘 배워두면 좋을 것 같다. 그래야 뉴스나 보도자료같은 문서들을 크롤링해서 저장한 다음에, 그걸 다시 뽑아오거나 재가공하는데 사용할 수 있지 않을까.
LLM과 API
API로 호출해서 답변을 받는 비용이 굉장히 싸기 때문에(!) 지금 많은 것들을 시도해보자. 게다가 오픈ai는 api로 질문하고 답변을 받는 규격화된 데이터 형식을 잘 맞추면 쉽게 쓸 수 있어서 이걸 최대한 활용하는 방법을 고민해보자.

부트캠프도 거의 막바지로 향하고 있다.
여태 많이 듣지 못한 강의들도 있는데, 강의도 좀 듣고 사이드 프로젝트도 열심히 해야지! 남은 기간도 뽜이팅!!!
'공부방 > Upstage AI Lab 4기' 카테고리의 다른 글
| [Coding] LinkedLists, Listnode (0) | 2024.12.27 |
|---|---|
| 데이터셋 분할 방법 (0) | 2024.12.23 |
| [IR] RAG 대회 정리 (2) | 2024.12.20 |
| [IR] 벡터 유사도를 계산하는 다양한 방법들 (0) | 2024.12.19 |
| [IR] 클로드로 프로젝트 관련 질문 싹다 몰아넣기 (0) | 2024.12.19 |

