오픈ai에서 api를 받아오는데 첨에 분명 무료라 했는데 계속 오류떠서 5달러 결제했다. 근데 결제하고 바로 안되고, 한참 뒤에 오류 없이 실행됨.
오늘 한 것:
파이썬으로 챗지피티 3.5랑 얘기하는데 위키피디아 문서 주고 그거 기반으로 답변받기
코드 하나하나 뜯어보자
import os
api_key = " "
os.environ["OPEN_API_KEY"] = api_key
os.environ.get("OPEN_API_KEY")os.environ은 환경 변수에 접근할 수 있게 해주는 매핑 객체이고, 환경 변수를 쓰면 보안이나 관리가 쉽기 때문이 쓰는 거라도 한다. (솔직히 이해 못했지만) 랭체인에서 중요한 파트는 아니니 일단 패스.
OpenAI 라이브러리를 임포트 해주는 것으로 시작!
from openai import OpenAI
client = OpenAI(api_key = api_key)
def get_response(prompt):
response = client.chat.completions.create(
model = "gpt-3.5-turbo",
messages=[{"role":"user", "content": prompt},],
)
return response.choices[0].message.content.strip()
#뒤에 달린 건 깔끔하게 만들어주려고.response = get_response("안녕! 넌 누구야?")
response이러면 챗지피티랑 연결!! response를 하니 '안녕하세요! 저는 인공지능 챗봇입니다. 무엇을 도와드릴까요?'라는 대답이 돌아온다.
이제 챗지피티가 참조해서 대답할 문서를 넣어주는데, 내가 직접 찾아서 넣어주는 방식을 먼저 보자.
지금 쓰고 있는 애가 gpt-3.5이므로, 소라가 나오기 전 모델이라 소라에 대한 지식이 없다. 그냥 소라에 대해서 물어보면 아무 대답이나 들려준다. 이걸 위키피디아에 있는 OpenAI 페이지의 sora 관련 부분을 복붙해서 아래와 같이 넣어준다. 프롬프트 안에 F-string으로 넣고 안에 [context] 와 [user qusiton]이라고 구분지어서 넣은 뒤에 쿼리를 user question에 넣어준다. 그러면 라이브러리는 이 문자열 전체를 API에 전송하고, 아래 f"""~~~~ """ 내용 전체가 프롬프트로 들어가 답변을 생성하는 것이다.
query = "OpenAI의 sora 모델에 대해서 설명해줘"
prompt = f"""
Utilizing the given context, please answer the question.
[context]
Text-to-video
Sora
Main article: Sora (text-to-video model)
Sora is a text-to-video model that can generate videos based on short descriptive prompts[214] as well as extend existing videos forwards or backwards in time.[215] It can generate videos with resolution up to 1920x1080 or 1080x1920. The maximal length of generated videos is unknown.
Sora's development team named it after the Japanese word for "sky", to signify its "limitless creative potential".[214] Sora's technology is an adaptation of the technology behind the DALL·E 3 text-to-image model.[216] OpenAI trained the system using publicly-available videos as well as copyrighted videos licensed for that purpose, but did not reveal the number or the exact sources of the videos.[214]
OpenAI demonstrated some Sora-created high-definition videos to the public on February 15, 2024, stating that it could generate videos up to one minute long. It also shared a technical report highlighting the methods used to train the model, and the model's capabilities.[216] It acknowledged some of its shortcomings, including struggles simulating complex physics.[217] Will Douglas Heaven of the MIT Technology Review called the demonstration videos "impressive", but noted that they must have been cherry-picked and might not represent Sora's typical output.[216]
Despite skepticism from some academic leaders following Sora's public demo, notable entertainment-industry figures have shown significant interest in the technology's potential. In an interview, actor/filmmaker Tyler Perry expressed his astonishment at the technology's ability to generate realistic video from text descriptions, citing its potential to revolutionize storytelling and content creation. He said that his excitement about Sora's possibilities was so strong that he had decided to pause plans for expanding his Atlanta-based movie studio.[218]
[user question]
{query}
"""
resp = get_response(prompt)
resp인간이 직접 자료를 찾아서 넣어주는 방식 말고, 위키피디아를 직접 찾아서 정보를 참조한 뒤에 답변을 해줬으면 좋겠다. 이럴 때는 Wikipedia API를 사용하여 "OpenAI"에 관한 페이지의 내용을 가져온다.
import requests
response = requests.get(
"https://en.wikipedia.org/w/api.php",
params = {
"action": "query",
"format": "json",
"titles": "OpenAI",
"prop": "extracts",
"explaintext": True
}
).json()
response이렇게 해서 response를 받으면 위키피디아 openai 문서에 있는 글이 그냥 쭉 나온다. 엄청 길다. json 파일(딕셔너리)이다. 여기서 본문 내용만 추출하고 싶다. 마침(?) 어제 배웠던 크롤링에서 json 뷰어를 활용해서 보면 좀 더 한눈에 들어온다.
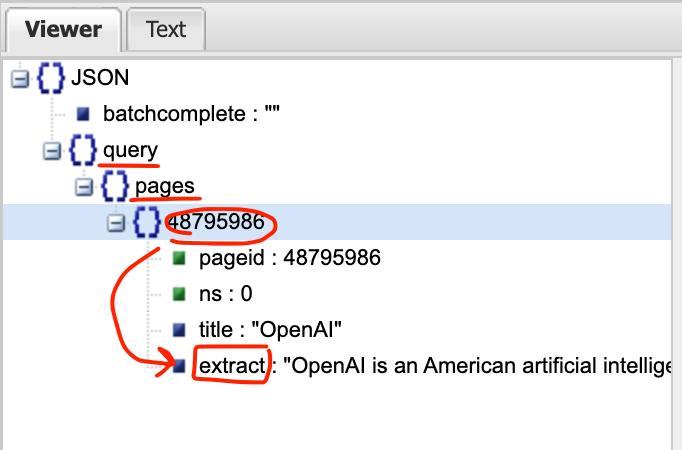
response['query']['pages'].values()
response라는 Json 파일에서 query라는 키값에, pages라는 키에 해당하는 밸류값(48795986)을 반환한다. iter()로 이 값들의 이터레이터를 생성하고, next()로 이터레이터의 첫 번째(그리고 유일한) 항목을 선택한다. 48795986 안에 extract가 내용. 이걸 text에 담아서 출력하면 내용만 나온다.
page = next(iter(response['query']['pages'].values()))
text = page['extract']
text이 코드가 필요한 이유:
- Wikipedia API 응답 구조: API 응답은 중첩된 딕셔너리 구조를 가집니다. 페이지 내용에 직접 접근하기 위해서는 이러한 구조를 탐색해야 합니다.
- 동적 페이지 ID: Wikipedia API는 페이지 정보를 페이지 ID를 키로 하는 딕셔너리 형태로 반환합니다. 이 ID는 동적으로 생성되므로, 코드는 ID를 모르는 상태에서도 내용을 추출할 수 있어야 합니다.
- 단일 페이지 가정: 이 코드는 API 요청이 단일 페이지에 대한 것이라고 가정합니다. 따라서 next(iter(...))를 사용하여 첫 번째(그리고 유일한) 페이지 정보를 추출합니다.
-> 이게 무슨 말인지 모르겠다. 갈길이 멀어 일단은 패스. 언젠가 이해하길 바라며.
어쨌든 text도 너무 길고 크다. 이걸 그대로 챗지피티한테 넘겨주기에는 너무 커서 잘라야한다. (청킹) 긴 문장을 잘라주는 함수를 만든다.
def get_chunk(text, chunk_size):
words = text.split()
chunks = [" ".join(words[i:i+chunk_size]) for i in range(0, len(words), chunk_size)]
return chunks
chunks = get_chunk(text, 128)
청킹청킹해서 잘라놓은 다음에는 임베딩을 한다. 텍스트 데이터를 챗지피티가 잘 이해할 수 있도록 수치화(?)하는 작업이라고 할 수 있다. 임베딩을 하면 텍스트 간의 유사도를 쉽게 계산할 수 있는데, 사용자가 질문한 쿼리와 가장 관련성 높은 텍스트 청크를 찾는데 사용된다.
이게 임베딩 하는 법. 함수로 만든다.
client.embeddings.create(input=["머신러닝"], model="text-embedding-3-small")
def get_embedding(text):
return client.embeddings.create(input=[text], model="text-embedding-3-small").data[0].embedding
#input=[text] 이거를 input=["text"]로 넣어서 실수함.임베딩이 잘 되었나 확인해보면 뭔가 엄청난 숫자 리스트들이 나온다.
embeddings = [get_embedding(c) for c in chunks]
embeddings
임베딩이 끝났으니 사용자의 질문 쿼리와 가장 관련성이 높은 텍스트 청크를 찾아야 한다. (정보 검색 시스템) sklearn 라이브러리의 cosine_similarity는 코사인 유사도 계산 함수라고 한다. 필요하니까 썼나 보다(? 일단 받아들여) query는 사용자의 질문이나 검색어, top_k는 가장 관련성 높은 청크를 몇 개 반환할 것인가를 쓰는 자리다.
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
def retriever(query, top_k):
q_emb = get_embedding(query)
sim_score = cosine_similarity([q_emb], embeddings)[0]
max_indices = np.argsort(sim_score)[::-1][:top_k]
retrieved_datas = [chunks[i] for i in max_indices]
return retrieved_datas위에서 get_embedding() 함수를 정의해놨으니, 이걸 q_emb으로 받고. 사용자가 질문한 문장의 쿼리의 임베딩 결과가 q_emb이다. 그리고 embeddings는 아까 위에서 정의했던 이거. 전체 내용의 청크를 임베딩한거.
embeddings = [get_embedding(c) for c in chunks]
embeddings이거 둘 사이의 유사도를 계산하는 식이 이거라고 한다. (머리가 어질어질)
sim_score = cosine_similarity([q_emb], embeddings)[0]그중에서 상위 k개를 뽑는 게 다음 코드인데, 유사도 점수를 내림차순으로 정렬해서 점수가 가장 높은 거부터 k개까지 인덱스를 선택한다. 그리고 선택된 인덱스에 해당하는 텍스트 청크를 리스트로 만든다.
contexts = retriever("OpenAI의 sora 모델에 대해 설명해줘", 3)
contexts근데 난 왜 결과가 소라랑 아무 관련 없어보이는 청크들이 나오냐왜 이러는지 모르겠네; 어디서부터 잘못된걸까. 중간에 짤렸나; -> get_embedding 함수에서 input을 "text"로 따옴표 치고 넣어서 그랬음!!
이제 드디어(?) 주어진 contexts를 참조해서 챗지피티가 답변을 만들 차례! 이걸 제너레이터라고 하고. 제너레이터 함수를 정의한다. 아까 사람이 직접 넣었던 형식과 유사하다.
def generator(query, contexts):
context = "\n\n".join(contexts)
prompt = f"""
Utilizing the given context, please answer the question
[context]
{context}
[user qustion]
{query}
"""
return get_response(prompt)이제 제너레이터에 물어보면! 제대로 된 답을 해준다.
generator("OpenAI의 sora 모델에 대해 설명해줘", contexts)
이게 기본적인 RAG를 활용해서 챗지피티 3.5모델로 답변받는 것을 구현해보았다. 내가 이해한 것대로 정리하면
- 키 받아와서
- Openai 라이브러리 임포트
- get_response 함수 만들어서 챗지피티에게 답변 받을 수 있게 하고
- 참조할 문서(여기서는 위키피디아) 페이지 내용을 넣어줌(위키피디아 API 써서 json파일로 내용 가져오고, 너무 기니까 문장들을 적당한 크기로 잘라준 다음에, 숫자로 임베딩까지 거침)
- 참조할 문서의 임베딩과 쿼리 임베딩을 비교해서 유사한 결과를 가져와서 contexts를 만듬
- contexts와 query를 제너레이터에 넣고 실행.
그 다음에 라마를 이용해서 위 과정을 단축하는 부분이 있는데, 라마는 그냥 안됨.. 왜 안됨..
라마와의 고군분투는 다른 포스팅에서.
'공부방 > Upstage AI Lab 4기' 카테고리의 다른 글
| 패스트캠퍼스 Upstage AI Lab 부트캠프 4기, "지원부터 OT까지, 초반부 진행 후기" (0) | 2024.08.09 |
|---|---|
| 라마 인덱스에서 빠르고 간편하게 RAG 수행하기 (0) | 2024.08.07 |
| 네이버 증권 데이터 크롤링 | f-string이 중요하네!! 디버깅 힌트 (0) | 2024.08.06 |
| RAG 발전에 중요한 영향을 끼친 3가지 논문 (0) | 2024.08.05 |
| Langchain과 RAG에 관한 찍먹 기본 지식 (1) | 2024.08.05 |


