머신러닝 경진대회 | 데이터 스케일링, 레이블 인코딩
2024.09.13 - [프로젝트] - 머신러닝 경진대회 | 결측치 메꿔주기
지난 편에 이어서... 결측치를 메꿔주고, (이상치도 조정해줘야하는데 이번 프로젝트에서 크게 다루지 않아서 패스.. 이상치는 데이터에서 첨부터 빼버림) 모델을 돌리기 전에 또 해야하는 것은 데이터 스케일링 작업이다.
일단 내가 이해한 대로 끄적여보자면, 스케일링은 모델이 학습을 할 때, 피쳐마다 제각각인 단위와 숫자 범위를 가지고 있어서 커다란 숫자가 있는 피쳐에 과하게 집중하는 것을 막기 위해서 작업해준다. 예를 들어서 아파트 넓이는 10~100 단위에서 왔다갔다 하고, 지역별 평균 가격은 몇 억 단위에서 왔다갔다하는데 두 개를 그대로 모델에 학습하라고 주면, 모델이 아파트 넓이는 숫자가 작아서 별로 중요하지 않다고 생각하고 학습이 덜(?) 될 수 있기 때문이다.
책에서는 정확하게 이렇게 적혀 있다. "(몇 가지를 제외하고) 머신러닝 알고리즘은 입력된 숫자 특성(피쳐)들의 스케일이 많이 다르면 제대로 작동하지 않습니다."
이번 경진대회에서 우리 팀은 스케일링을 할 때, minmax와 RobustScaler와 Box-cox 변환 3가지를 썼다. 어떤 피쳐를 무슨 스케일러에 넣어야할지 고민했었는데, 시간이 빠듯해서 충분히 고민해보지 못했던 것 같다. (개인적으로 스케일링이 정확히 뭔지 파악을 못하고 있었던 탓도 크고ㅠㅠ) 어쨌든 뒤늦게 정리하면서라도 공부해보자.
Feature scaling
스케일링은 이상치에 영향을 많이 받기 때문에, 스케일링을 하기 전에 이상치를 처리해주는 것이 좋다.
모든 피쳐의 범위를 똑같이 만들어주는 방법으로는 min-max 스케일링과 표준화가 대표적이다. minmax스케일링은 normalization 정규화라고도 부르는데, 표준화랑 정규화가 헷갈리니까 그냥 minmax라고 하자. (그렇다고 꼭 모든 피쳐의 범위를 똑같이 만들어줄 필요는 없음)
minmax (=Rescaling (min-max normalization))
minmax는 특성을 0에서 1 범위 안으로 바꿔준다. 데이터에서 최솟값을 빼고, 최댓값과 최솟값의 차이로 나눈다. X-Xmin을 하면 모든 데이터에서 최소값을 빼는 것인데 Xmin 값이 들어가면 Xmin - Xmin = 0으로, 데이터가 0부터 시작하도록 만들어준다. 원래 10, 20, 30 이런 데이터였으면, 0, 10, 20 이렇게 범위를 옮겨주는 것. 그리고 Xmax - Xmin 은 데이터의 전체 범위로, 전체 구간의 길이로 나눠주면 각 데이터가 전체 범위에서 차지하는 비율을 계산하는 셈이 된다. 결과적으로 데이터가 0과 1 사이의 값으로 변환된다.

X_std = (X - X.min(axis=0)) / (X.max(axis=0) - X.min(axis=0))
X_scaled = X_std * (max - min) + min예제)
import numpy as np
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
# 샘플 데이터 생성
data = {
'height': [170, 180, 165, 175, 190],
'weight': [70, 85, 60, 75, 90],
'age': [30, 45, 25, 35, 50]
}
df = pd.DataFrame(data)
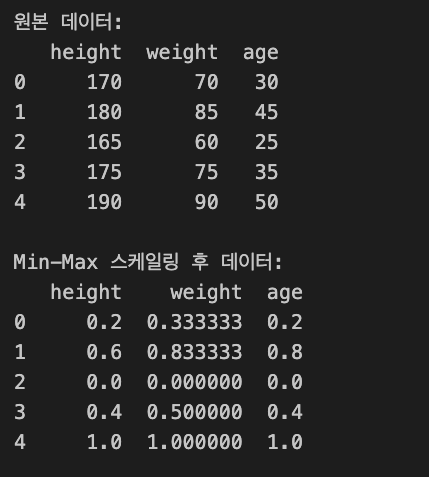
print("원본 데이터:")
print(df)
# Min-Max 스케일링 적용
scaler = MinMaxScaler()
scaled_data = scaler.fit_transform(df)
scaled_df = pd.DataFrame(scaled_data, columns=df.columns)
print("\nMin-Max 스케일링 후 데이터:")
print(scaled_df)각 피쳐들이 minmax로 스케일링된 결과를 이렇게 볼 수 있다. 데이터의 상대적 위치를 비교하기 좋다.
참고로 플젝에서 썼던 코드..
from scipy import stats
from sklearn.preprocessing import MinMaxScaler
#target_feature를 스케일링 할 때
min_max_scaler = MinMaxScaler()
scaled = min_max_scaler.fit_transform(target_feature)
#함수화
def minmax_scale_features(df, columns_to_scale):
# MinMaxScaler 객체 생성
scaler = MinMaxScaler()
# 지정된 열들에 대해 스케일링 수행
df[columns_to_scale] = scaler.fit_transform(df[columns_to_scale])
return df, scaler
#함수 사용
columns_to_scale = ['전용면적(㎡)']
df, scaler = minmax_scale_features(concat, columns_to_scale)
Standardization(Z-score Normalization)
표준화(Standardization)는 평균을 먼저 빼고, 표준편차로 나눈다. 평균이 0, 표준편차가 1이 되도록 변환한다. 평균이 0이 된다는 것은 데이터의 중심점을 0으로 이동시킨다는 것과 같은데, 원래 데이터에서 평균값을 빼서 모든 데이터들이 0 근처에서 왔다갔다하도록 만들어준다. 데이터 위치는 바뀌지만, 데이터들 사이의 상대적 간격은 동일하다. 그리고 이 값을 표준편차를 1로 만들어준다.
ㅇZ = (X - μ) / σ
표준화된 값 = (X - 평균) / 표준편차


minmax가 0~1사이로 값의 범위를 제한했다면, Standardization은 특정 값으로 범위를 제한하지 않는다. minmax처럼 데이터의 위치와 스케일은 조정되고, 기본적인 분포 형태는 그대로 가진다.
minmax에 비해 standardization이 이상치에 덜 민감하다. (minmax는 이상치에 굉장히 민감). minmax는 데이터를 균일하게 0~1로 조정하므로 원본 분포가 조금 변형될 수도 있지만 standardization은 원본의 분포를 더 잘 유지한다.
Robust Scaling
Robust는 minmax처럼 특성들을 같은 스케일로 맞추지만, 데이터의 중앙값(median)이 0, IQR(Interquartile Range)이 1이 되도록 스케일링하는 기법이다. 이상치의 영향을 줄이고 싶을 때 쓰는 스케일링.

where Q1(x),Q2(x),Q3(x) are the three quartiles (25th, 50th, 75th percentile) of the feature.
Box-cox
Box-cox가 어려웠는데, 분포가 한쪽으로 치우쳐져있거나 꼬리가 길거나 이런 경우에 좀더 중앙에 모이도록 바꿔주는 변환이다.
https://youtu.be/-kkDWmRsOLo?si=uFhMOOxWhDw_Desp
이런 스케일링은 수치형 변수에 대해서만 적용할 수 있다. 수치형 변수들을 이렇게 스케일링까지 해주고난 뒤에, 범주형 변수를 숫자로 만들어주는 레이블 인코딩을 진행해줬다.
범주형 변수 레이블 인코딩
레이블 인코딩은 문자열로 된 범주형 변수를 숫자로 바꾸는 것인데, 예를 들면 삼성전자를 1, LG를 2, 카카오를 3 이런 식으로 각 범주값을 하나의 숫자와 매치시켜준다. 원-핫 인코딩도 있는데, 1과 0으로만 표현하는 방식이다.

레이블 인코딩은 범주 간에 순서가 있거나, 중요도가 다르거나 (1등, 2등, 3등 이런 느낌으로... 상, 중, 하), 범주 개수가 많을 때 쓰면 효율적이라고 한다. 대신 숫자가 1, 2, 3 이렇게 들어가니까 blue가 green의 2배라고 잘못 해석할 수도 있다. 클로드 말로는 의사결정 트리나 Random Forest, Gradient Boosting 머신(XGBoost, LightGBM)에 적합하다고 하다.
반면 원핫 인코딩은 범주 사이에 순서가 없고 범주 사이의 관계가 명확히 구분될 때 쓰면 좋다고. 원핫이 선형 모델이나 로지스틱 회귀, 신경망에 더 주로 쓰인다고 한다.