2024.09.02 - [프로젝트] - 머신러닝 경진대회 1 | 데이터 분석 EDA 혼자 해보기
지난 포스팅보다 좀 더 본격적으로, EDA를 책을 보며 따라가봤다. 먼저 데이터 탐색을 위해 복사본을 생성한다.
traindata = pd.read_csv('/data/ephemeral/home/data/train.csv')
traindata_copy=traindata.copy()
각 피쳐의 특징을 조사해보자
info() 메서드를 사용해 데이터에 대해 간략한 개요를 확인한다. 확인할 수 있는 주요 정보는, 52개의 컬럼(피쳐)과 1118822개의 행(row)가 있다는 사실, 인덱스의 범위는 0부터 1118821까지이며, 각 컬럼의 이름과 컬럼의 데이터 특성을 알 수 있다.

숫자 아니면 object인데 object에 어떤 데이터가 들어갔다는 건지 조금 모호한 것들이 있다. 이럴 때 value_count() 메서드를 쓰면 피쳐 안에 어떤 카테고리로 값들이 구분되고 각 카테고리마다 몇 개의 데이터가 있는지 확인할 수 있다.
예를 들어서 '시군구' 피쳐에 들어간 데이터가 어떻게 있는지 보면, "서울시 노원구 상계동"이라는 값을 가진 데이터가 44948개나 있다. Length: 339는 '시군구' 컬럼에 존재하는 고유한 값(유니크한 값)의 개수를 의미하는데, 이 데이터에는 339개의 구-동을 갖는 데이터들이 있다는 뜻. 그리고 빈도수는 정수형으로 표현됐다.

이런 식으로 피쳐의 이름과, 타입(범주형, 정수/부동소수, 최댓값/최솟값 유무, 텍스트, 구조적인 문자열 등), 누락된 값의 비율
잡음의 정도와 잡음의 정도(확률적, 이상치, 반올림 에러 등..), 분포 형태 등을 살펴본다.
특이했던 피쳐
11 해제사유발생일 5983 non-null float64
Null 이 대부분이였는데, 이게 뭔지 찾아보니 거래가 해제된 경우를 의미하는 것 같다. 정상적인 계약 거래면 해제사유가 발생하지 않았으니 Null값이 당연하고. 여기에 값이 들어간 경우는 거래가 취소된 건이라는 의미가 되므로 발생일에 값이 있는 row는 아예 데이터셋에서 빼주는 게 좋을 것 같다.
15 k-단지분류(아파트,주상복합등등) 248131 non-null object 결측치 아파트로 대부분 바꿔도 될 듯
19 k-세대타입(분양형태) 249259 non-null object
k-세대타입(분양형태) NaN 869563 분양 206371 기타 40686 임대 2202 -> 임대 2022건은 뭐지? 임대는 빼줘야한느거 아닌가 싶기도..
24 k-전체세대수 249259 non-null float64
k-전체세대수 NaN 869563 5678.0 3028 5040.0 2816 4494.0 2589 4424.0 2562 ... 494.0 2 514.0 2 799.0 1 243.0 1 1395.0 1 널값이 많긴한데.. 이것도 나름 중요한 피쳐일 것 같아서. 결측치 어떻게 처리해주면 좋을지 고민해보면 좋을 듯.
25 k-건설사(시공사) 247764 non-null object
29 k-주거전용면적 249214 non-null float64
42 건축면적 249108 non-null float64
43주차대수249108 non-null float64
NaN 869714 0.0 17945 2.0 3413 1.0 2852 널값은 그렇다 쳐도 0대가 17945건은 뭐지...
주저전용면적이나 건축면적, 주차대수는 집의 크기나 세대수랑 연관이 있을 수 있어서, 이것도 어떻게 활용할 수 있으면 좋을듯
48 좌표X 249152 non-null float64
49 좌표Y 249152 non-null float64
이건 위치 정보이므로.. 결측치를 어떻게 채워넣으면 좋을지 고민이 필요할듯
describe() 메서드는 숫자형 데이터의 특성을 요약해준다. 숫자형으로 표현된 23개 피쳐들만 나왔다.

데이터 형태를 빠르게 검토하고 싶다면 각 숫자형 특성을 히스토그램으로 그려보는 것도 좋다. 히스토그램을 그렸는데 첨에 한글이 다 깨져서 나왔다. 맥북에서 한글 폰트를 이렇게 지정해주니 됐다! 서버컴에는 폰트 따로 다운로드 받아놓고 그걸로 지정해주니 됨.. (이걸로 한 시간 헤맨 거 잘 한 짓이냐ㅠ)
#맥북에
import matplotlib.pyplot as plt
from matplotlib import rc
rc('font', family='AppleGothic')
plt.rcParams['axes.unicode_minus'] = False
#서버컴에
from matplotlib import rc
rc('font', family='NanumGothic')
plt.rcParams['axes.unicode_minus'] = False어렵게 얻은 히스토그램 그래프ㅋㅋㅋ (일단 쓸모없어보이는 피쳐는 모두 빼주고 히스토그램을 그렸다.)
revisedata = traindata_copy[
['시군구', '전용면적', '계약년월', '건축년도', '해제사유발생일', 'k-전체세대수', 'k-건설사(시공사)',
'k-주거전용면적', '건축면적', '주차대수', '좌표X', '좌표Y', 'target']]
#히스토그램
revisedata.hist(bins=50, figsize=(12,8))
plt.show
데이터셋에는 x, y 좌표로 위도와 경도 데이터도 주어져있다. 이것도 시각화해보면 서울 모양이 대충 나온다. 서울 대부분의 지역에서 고르게 데이터를 가지고 온 것을 같다. (노원구가 가장 많았지만)
traindata_copy.plot(kind="scatter", x = "좌표X", y = "좌표Y", grid=True)
plt.show()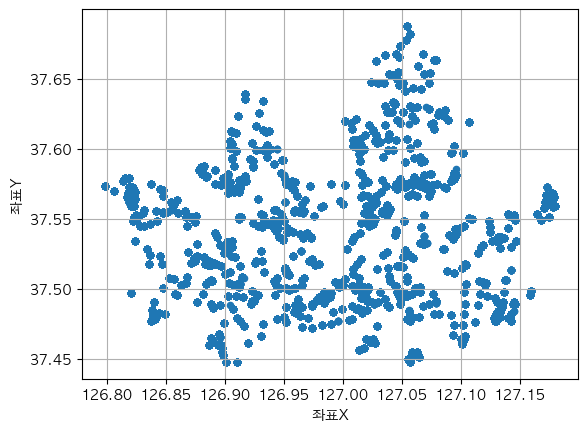
새롭게 정리한 reviseddata의 피쳐들의 결측치 비율을 확인하고 이제 어떻게 결측치를 채워줄지 고민해보자.

본격적으로 결측치와 이상치를 변환해주기 전에, 해제사유발생일의 null값이 아닌 row를 먼저 제거하고, 해제사유발생일 컬럼을 아예 지워버려야겠다. 그러면 취소된 거래를 없앨 수 있겠지?
revisedata_filtered = revisedata[revisedata['해제사유발생일'].isnull()]
revisedata_filtered.info()원래 1118822개 row에서 해제사유발생일이 null이 아닌 값인 5983이 빠져서 1112839개 row가 남았다.
해제사유발생일은 이제 전부 Null값이 됐으니 이제 컬럼 자체를 통째로 없애줘버려야겠다.
revisedata_filtered = revisedata_filtered.drop('해제사유발생일', axis=1)
이제 이상치와 결측치 메꿔주기 ...
베이스라인 코드 예제를 보면 연속형 변수는 선형보간으로 대체하고 범주형 변수는 NULL이라는 임의의 범주로 대체했다.
'공부방 > Upstage AI Lab 4기' 카테고리의 다른 글
| 머신러닝 경진대회 | 데이터 스케일링, 레이블 인코딩 (4) | 2024.09.16 |
|---|---|
| 머신러닝 경진대회 | 결측치 메꿔주기 (0) | 2024.09.13 |
| 머신러닝 경진대회 1 | 판다스로 데이터 합치기 (1) | 2024.09.06 |
| VS Code 터미널에 브랜치 이름 표시하기 (0) | 2024.09.04 |
| GIT | Git 쓰는 법 다시 정리!!! (초보용) (0) | 2024.09.04 |



